在上一篇 AI助力博客创作:自动生成摘要与标签的实战指南 中使用 AI 自动生成文章摘要和 Tags, 这次我们依旧利用 AI 来帮我们为文章进行智能分类.
理解分类和标签
分类 (Categories)
在图书馆中,每本书都会被归入一个特定的分类。我们所熟知的图书馆分类系统,例如杜威十进制分类法,便是依据主题将书籍进行系统划分的工具。杜威分类法将书籍划分为十个主要类别(如哲学、社会科学、语言学、自然科学等),并在此基础上根据主题进一步细分为子类。
将这一概念类比至博客分类,可以视作一种类似图书馆的分类体系,旨在将文章按照主题进行有序组织。例如,“编程技术”作为一个主要类别,类似于图书馆中的“技术科学类”,在此主类别下,又可细分为“前端开发”、“后端开发”、“数据库”等子分类,这与图书馆的子类系统颇为相似。
主要特点:
- 层次感强:一个大类下可以有多个子分类,比如 “编程” 下面可以再分成 “Java”、“Python” 等。
- 一个分类为主:每篇文章通常会归入一个主要的分类,帮助读者明确文章的核心主题。
作用:
- 帮助读者导航:让人一进来就知道文章讲的是哪个大方向。
- SEO 加分:搜索引擎更容易搞清楚你的网站架构,利于提升排名。
示例:
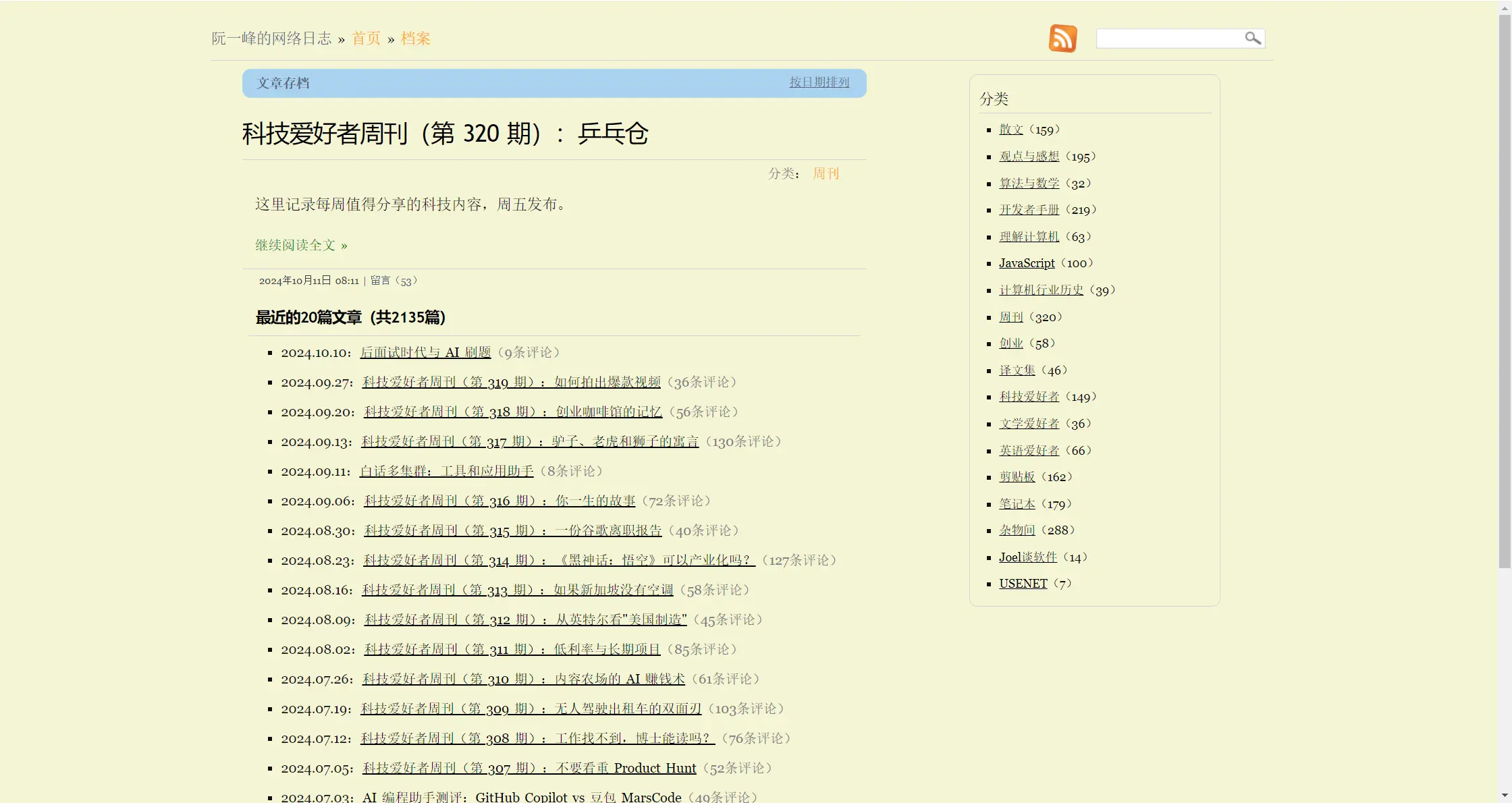
阮一峰的网络日志:阮一峰的博客分类清晰,比如 “科技”、“翻译”、“编程” 等,帮助读者快速找到感兴趣的内容。
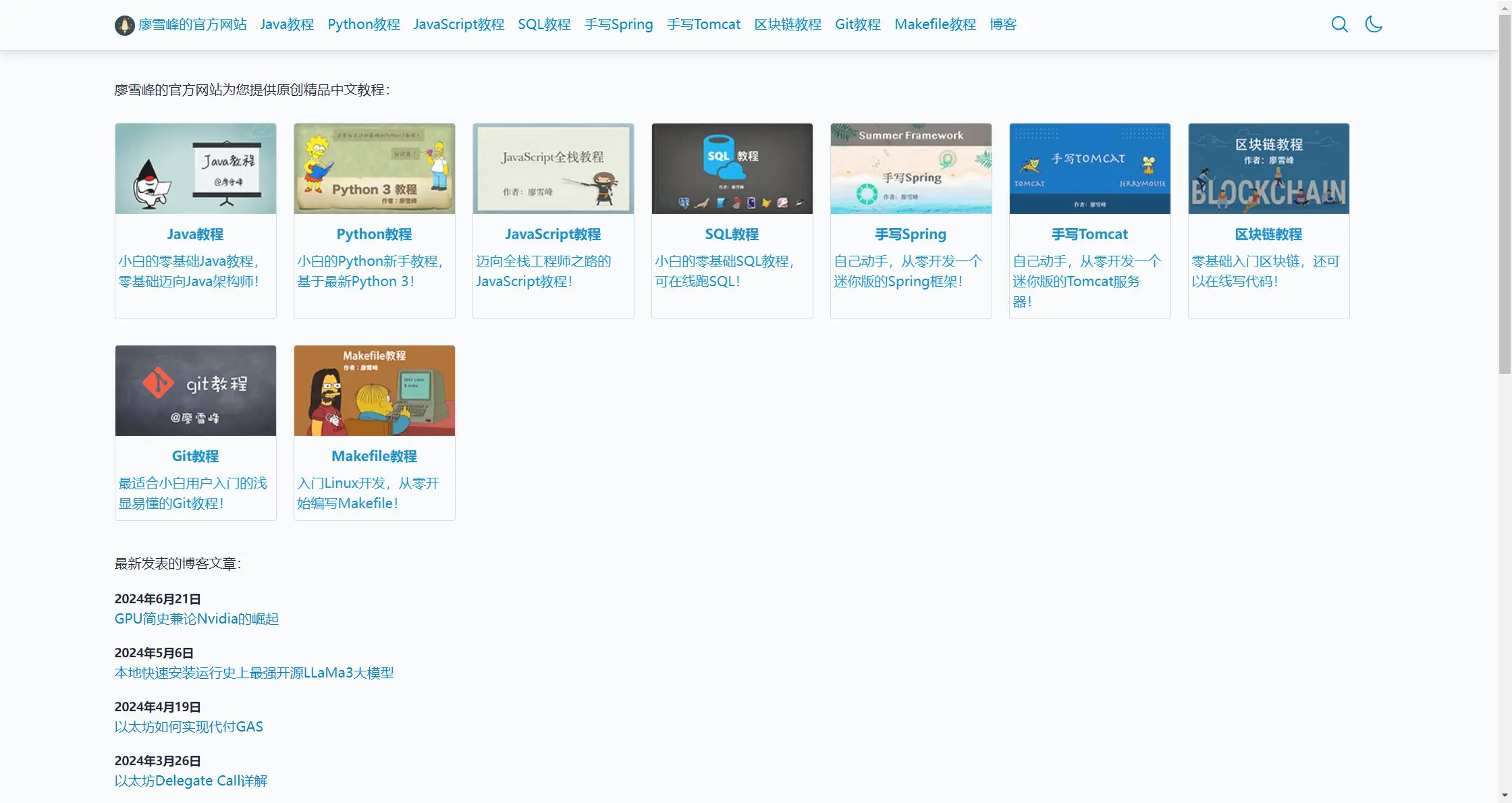
廖雪峰的官方网站:廖雪峰的站点分类以 “Python”、“Git” 等技术内容为主,每个大类下都有丰富的教程。
标签 (Tags)
除了按类别分类,图书馆还会给每本书打上关键词,用来描述书的内容和特点。这些关键词可以帮助读者从多个角度去搜索和查找书籍,主题词表(也称为 “标引”)就是起到这样的作用。比如一本书可能既和“人工智能” 有关,又和 “深度学习” 有关,那么图书馆会给它同时打上 “人工智能”、“深度学习” 这两个主题词。
类比到博客标签就像图书馆给书籍打的关键词,它们没有层次关系,但能从不同维度描述文章的内容。比如一篇关于 “Python 爬虫” 的文章,可能打上 “Python”、“爬虫”、“数据抓取” 等多个标签,这样读者可以通过任意一个标签找到文章。
特点:
- 平面化,没有层次:标签不像分类那样有父子结构,所有标签是平等的。
- 一篇文章可以有多个标签:标签更多是帮作者从多个角度来描述文章的内容。
作用:
- 方便用户查找:读者通过标签,可以找到更多相似主题的文章,体验会好很多。
- 提升搜索优化:多打一些标签,也能让搜索引擎更容易抓取到你的文章内容。
分类和标签的区别
分类和标签的关系有点像主菜和配菜。分类是主线,明确说明这篇文章属于哪个 “菜系”,比如“编程”、“产品管理”;而标签则是附加的调味料,说明这道“菜” 有哪些特点,比如“Python”、“效率工具”。
- 分类是结构化的、层次感强的,用来划分大的内容模块。
- 标签是灵活的,用来描述文章的细节和具体内容,通常用来补充分类无法覆盖到的多维度信息。
举个例子:一篇介绍用 Python 写爬虫的文章,分类可能是 “编程技术 - Python”,而标签可以是“Python”、“爬虫”、“数据抓取” 等,这样读者既能通过分类找到这篇文章,也能通过标签找到相关的文章。
如何设计自己的分类和标签
最开始也没有太多的思路,所以就去看看好的博客网站怎么做的;
这里推荐一个开源项目:中文独立博客列表,这里面记录了大量的中文独立博客网站;
简单总结一下:
分类要简洁清晰:分类不宜过多,也不要太乱,一般来说,10 个左右的大分类比较合适,最好一眼就能看懂。每个大分类可以有几层子分类,这样也更有条理。
标签要灵活丰富:标签没有数量限制,可以根据每篇文章的内容灵活添加。想想读者可能会用哪些关键词来查找这篇文章,然后用这些词作为标签。
分类和标签的结合是最有效的组织方式:分类帮助梳理大的结构,标签则帮助覆盖到更多内容细节。
举个例子:
- 编程技术
- 生活感悟
- 产品经理
- 博客建站
- 数据科学
在编程技术下,可以细分成前端开发、后端开发、移动开发,然后每篇文章再打上具体的标签。比如一篇文章关于用 Vue.js 写前端项目,分类是编程技术 - 前端开发,标签可以是 Vue.js、JavaScript、前端优化。
以上是来自下面的作者的博客内容
====================================
文章作者: MinChess
文章来源: 九陌斋—MinChess's Blog
文章链接: https://blog.jiumoz.com/archives/bo-ke-wen-zhang-zen-me-she-ji-fen-lei-yu-biao-qian
版权声明: 内容遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。我的分类设计
大概参考了一下别人的分类已经对自己今后需要主攻的方向后, 将现在的博文暂时分为一下几类:
| 分类名称 | 内容描述 |
|---|---|
| 新时代码农 | 只要是涉及到开发相关的博客, 都划分到此分类下, 不再划分如 Java, 中间件, 数据库等细分分类 |
| HomeLab:中年男人的快乐源泉 | HomeLab 相关的文章 |
| AI:人工智能 | AI, LLM, RAG, AIGC 等相关的文章 |
| 生活:生下来活下去 | 个人生活记录 |
| 转载内容 | 转载的优秀博文 |
| 经验分享 | 分享自己的经验总结 |
| 我的项目 | 记录自己的开源项目 |
| 闲聊杂谈 | 想到什么写什么 |
| 软件推荐 | 推荐用着顺手的软件 |
| 好物推荐 | 推荐用着顺手的工具 |
| 翻译内容 | 学习一下英语, 翻译一下外网优秀的博文 |
使用 AI 对文章进行分类
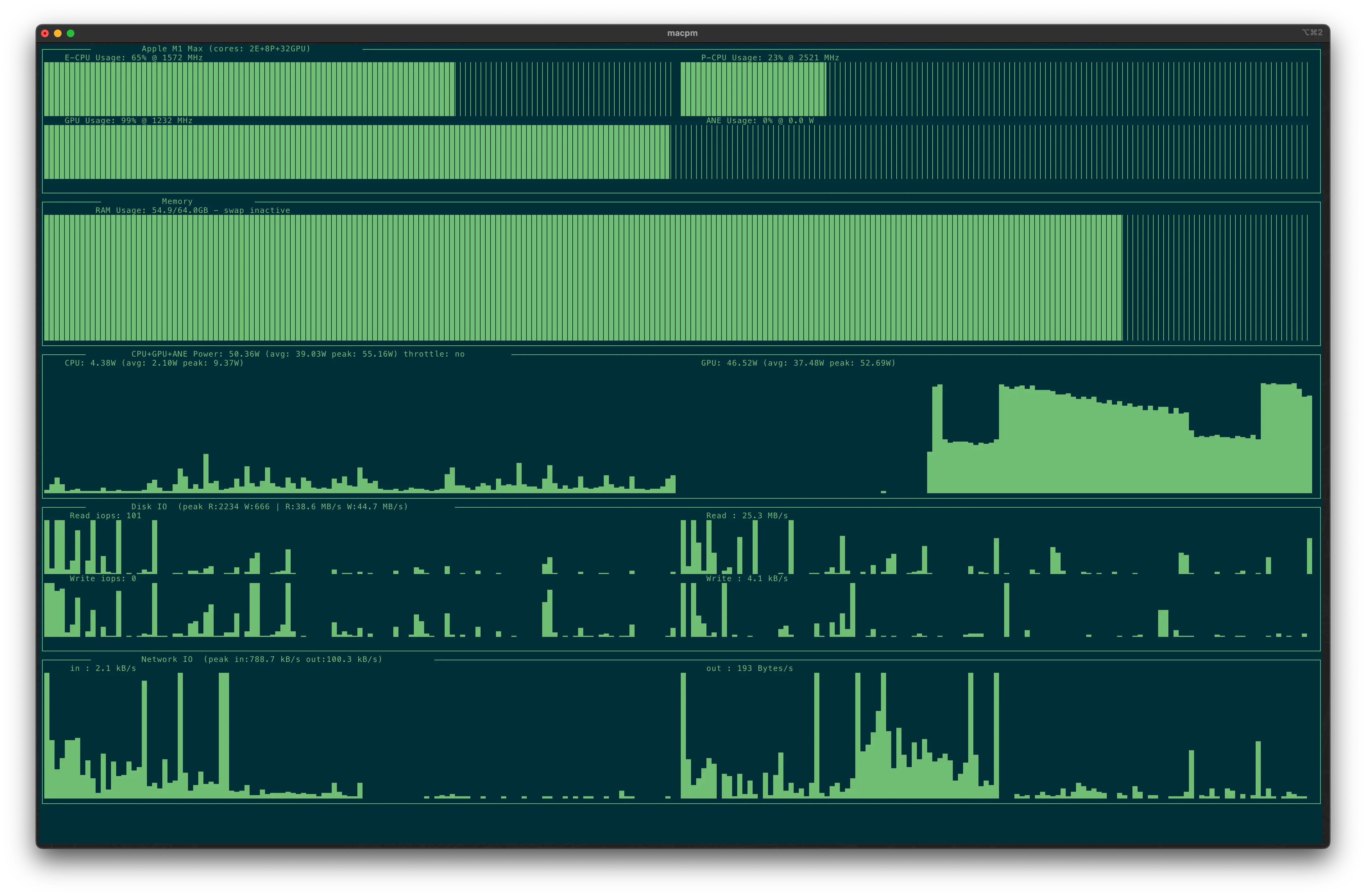
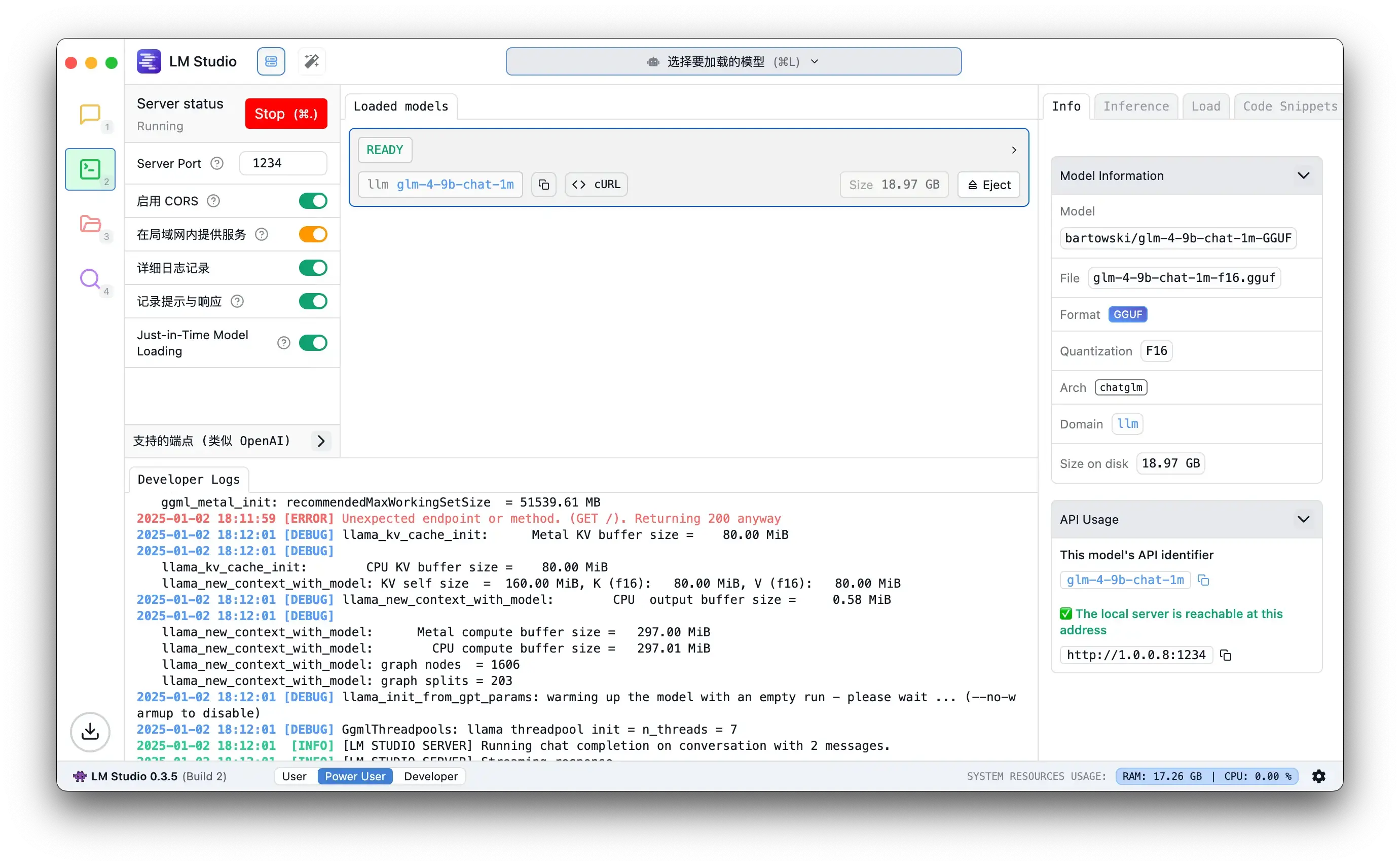
在上一篇 AI助力博客创作:自动生成摘要与标签的实战指南 使用的是 Ollama, 但是因为模型的原因生成的结果不是特别满意, 所以这次使用 LM Studio 作为服务端为脚本提供 AI 服务, 模型选择的是 glm-4-9b-chat-1m, 使用的是 F16 的版本. 模型有 18.97GB, 在 64G 内存的 Macbook Pro Apple M1 Max 跑起来还算流畅, 不得不称赞一下 Apple M 系列的芯片, 只有在跑模型的时候才会烫手, 其他时候都非常安静.
在使用模型时, GPU 基本上都是 100%:
macOS 本地跑模型的话比较推荐使用 LM Studio, 模型下载, 本地服务, OpenAI API 兼容接口等等常规功能一应俱全:
需求整理
- 提供自动和手动 2 种方式, 自动则调用 AI 直接使用推荐的分类替代当前的分类, 手动的话则通过交互方式选择分类;
- 因为 AI 生成推荐的分类需要一定时间, 交互式也需要时间去判断选择, 所以需要使用 2 个线程执行这 2 个操作, 避免等待时间过长;
- 提供一个额外的文本记录已被处理过的文件, 避免重复处理;
实现
generate_category.py
基于上述需求, 使用 python 写一个简单的脚本:
from pydantic import BaseModel
from openaiapi.client import generate as client_openaiapi
from ollama.client import generate as client_ollama
import unittest
import json
from utils import clean_md_whitespace
class Document(BaseModel):
recommend: str
options: list[str]
def generate(content, type="openaiapi", auto_replace=True):
categories ={
"options": [
"新时代码农",
"HomeLab:中年男人的快乐源泉",
"AI:人工智能",
"生活:生下来活下去",
"转载内容",
"经验分享",
"我的项目",
"闲聊杂谈",
"软件推荐",
"好物推荐",
"翻译内容"
]
}
if not auto_replace:
return json.dumps(categories)
# 构造 prompt
prompt = f"""
请根据我提供给你的博客内容的核心主题为其选择一个最合适的文章分类。
附加说明:
1. 生成的分类必须是我给定的以下几个选项之一:
{categories['options']}
2. 如果涉及到编程与开发相关的关键字, 比如 Java, Spring, Redis, Rabbitmq, SQL, MySQL, JVM等, 全部划分到 '新时代码农' 这个分类。
3. 你必须以JSON格式响应,键为'recommend',值是字符串格式的分类名称, 键为'options',值是我给定的分类列表。
"""
if type == "openaiapi":
return client_openaiapi(prompt, content, response_format=Document)
elif type == "ollama":
prompt = prompt + f"""
请分析'CONTENT START HERE'和'CONTENT END HERE'之间的文本
CONTENT START HERE
{content}
CONTENT END HERE
"""
return client_ollama(prompt)得益于 OpenAI API 的结构化输出, 我们可以自定义最终返回的结构:
class Document(BaseModel):
recommend: str
options: list[str]recommend: AI 生成的推荐分类;options: 我的文章分类;
上述代码会按照我给定的结构返回最终结果, 我们只需要根据规则提取指定字段即可.
这里还简单的分装了一下 Ollama 和 OpenAPI API, 一个是为了兼容其他脚本, 二是想测试一下不同的服务提供者对提示词的响应区别:
LLM API
Ollama Client
import requests
def generate(prompt, model="qwen2"):
# 设置 Ollama API 的 URL
url = f"http://localhost:11434/api/generate"
data = {
"model": model,
"prompt": prompt,
"format": "json",
"stream": False
}
# 发送 POST 请求到 Ollama API
try:
response = requests.post(url, json=data, stream=False)
response.raise_for_status() # 检查请求是否成功
data = response.json()
# 提取生成的摘要
if "response" in data:
return data["response"]
else:
print("没有从响应中获取到摘要内容!")
return None
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
return NoneOpenAI API
from openai import OpenAI
def generate(prompt, content, usemodel="glm-4-9b-chat-1m", response_format=None):
client = OpenAI(base_url="http://localhost:1234/v1", api_key="lm-studio")
completion = client.beta.chat.completions.parse(
model=usemodel,
messages=[
{"role": "system", "content": prompt},
{"role": "user", "content": content}
],
temperature=0.7, # 根据需要调整这个参数
response_format=response_format, # 动态传入的格式
)
return completion.choices[0].message.contentreplace_category.py
最后是替换分类的脚本:
import os
import sys
import time
import json
import threading
import queue
from utils import log, get_process_md_files, split_md, dump_md_yaml, clean_md_whitespace, get_md_category, save_processed_file, load_processed_files
from generate_category import generate as generate_category_from_ai
# 配置路径
PROCESSED_FILE = "./processed_category_files.txt" # 已处理的文件记录
# 全局队列
task_queue = queue.Queue()
result_queue = queue.Queue()
def fetch_category_from_ai(md_file, auto_replace111):
"""
调用 ai 接口生成分类。
这是占位函数,具体逻辑请实现后替换。
"""
content = clean_md_whitespace(md_file)
# print(blog_content)
category = generate_category_from_ai(content, auto_replace=auto_replace111)
if category:
return json.loads(category)
return None
def replace_md_category(md_file, original_categorie, new_category):
# 调用函数并获取 body 和 data
result = split_md(md_file)
if not result:
return
data = result['data']
body = result['body']
# 替换 categories
data['categories'] = [new_category]
dump_md_yaml(md_file, data, body) # 保存更新后的 YAML 和 body
log(f"修改分类: {md_file}")
log(f"{original_categorie} -> {new_category}")
def ai_worker(auto_replace):
"""
负责调用 ai 的线程。
"""
while True:
md_file = task_queue.get()
if md_file is None: # 检查是否结束
break
data = fetch_category_from_ai(md_file, auto_replace)
result_queue.put((md_file, data))
task_queue.task_done()
def interactive_worker(auto_replace):
"""
负责交互式处理的线程。
"""
processed_files = load_processed_files(PROCESSED_FILE)
while True:
md_file, data = result_queue.get()
if data is None: # 标识当前任务还未完成,阻塞等待
log(f"正在等待为 {md_file} 生成分类...")
result_queue.put((md_file, None)) # 重新将任务放回队列以等待生成完成
time.sleep(1) # 等待片刻再检查
continue
if not data: # 如果明确返回空列表,说明分类生成失败
log(f"未生成分类,跳过 {md_file}")
continue
original_category = get_md_category(md_file)
if auto_replace:
# 提取分类列表
new_category = data.get("recommend", '')
replace_md_category(md_file, original_category, new_category)
else:
# 提取分类列表
options = data.get("options", [])
# 处理分类逻辑
print(f"\n为文件 {md_file} 生成的分类如下:")
for i, option in enumerate(options):
print(f"{i + 1}: {option}")
choice = input("请选择分类编号: ").strip()
if choice.isdigit():
choice = int(choice)
if choice > 0 and choice <= len(options):
new_category = options[choice - 1]
replace_md_category(md_file, original_category, new_category)
else:
log(f"未替换 {md_file} 的分类。")
save_processed_file(md_file, PROCESSED_FILE)
processed_files.add(md_file)
result_queue.task_done()
def main():
# True 使用 AI 自动替换, False 使用交互式替换
auto_replace = True
dicts = get_process_md_files(sys.argv[1:])
# 确保发布目录存在
os.makedirs(dicts.get('publish_dir'), exist_ok=True)
md_files_to_process = dicts.get('files')
# 加载已处理文件
processed_files = load_processed_files(PROCESSED_FILE)
# 获取所有 Markdown 文件
md_files_to_process = [f for f in md_files_to_process if f not in processed_files]
# 检查是否有未处理的文件
if not md_files_to_process:
log("没有需要处理的 Markdown 文件。")
return
# 启动 Ollama 调用线程
threading.Thread(target=ai_worker, args=(auto_replace,), daemon=True).start()
# 将任务添加到队列
for md_file in md_files_to_process:
task_queue.put(md_file)
# 启动交互线程
threading.Thread(target=interactive_worker, args=(auto_replace,), daemon=True).start()
# 等待任务完成
task_queue.join()
result_queue.join()
log("==================category 处理完成==================")
if __name__ == "__main__":
main()功能概述:
- 读取 Markdown 文件:从指定目录读取 Markdown 文件。
- 调用 AI 接口生成分类:通过 AI 接口生成新的分类。
- 替换分类:将生成的分类替换到 Markdown 文件的 Front-matter 中。
- 记录已处理文件:将已处理的文件记录保存到文本文件中,以便下次运行时跳过这些文件。
工作流程
- 初始化:
- 读取配置文件和已处理文件列表。
- 获取待处理的 Markdown 文件列表。
- 启动工作线程:
- 启动 AI 工作线程,从
task_queue中获取任务并调用 AI 接口。 - 启动交互式工作线程,从
result_queue中获取 AI 生成的分类并处理用户输入。
- 启动 AI 工作线程,从
- 处理任务:
- AI 工作线程调用 AI 接口生成分类,并将结果放入
result_queue。 - 交互式工作线程从
result_queue中获取结果,根据用户输入替换分类,并保存已处理文件。
- AI 工作线程调用 AI 接口生成分类,并将结果放入
- 结束:
- 所有任务完成后,打印处理完成的消息。
手动和自动需要去脚本中修改一下
# True 使用 AI 自动替换, False 使用交互式替换
auto_replace = True总结
目前已经使用 AI 替换了博文的标题, Tags, 分类以及生成摘要, 后续继续研究一下将所有博文使用 AI 创建一个知识库, 在站点上提供一个 AI 对话功能, 现在调研的有 Dify, 扣子, MaxKB, FastGPT 以及 PostChat, 这类都支持 WebSDK 集成, 等有成果的时候再总结一下.
上述代码已经上传到 仓库.