
在信息爆炸的时代,如何让您的博客内容在浩如烟海的资讯中脱颖而出,成为吸引读者眼球的关键。而标签和摘要在这一过程中扮演着至关重要的角色。今天,我们将探讨如何利用 AI 技术为博客自动生成标签和摘要,从而提升内容的可发现性和阅读体验。
标签与摘要的重要性
标签是博客内容的“关键词”,它们能够简洁、直观地反映文章的主题和核心内容。好的标签不仅有助于搜索引擎优化(SEO),还能引导读者快速找到感兴趣的内容。 摘则是博客的“门面”,它以简短的文字概括文章的主要内容,激发读者的阅读兴趣。一个吸引人的摘要能够有效地提高文章的点击率。
AI 在标签和摘要生成中的优势
传统上,标签和摘要的生成依赖于人工撰写,这不仅耗时耗力,而且难以保证一致性和准确性。而 AI 技术的引入,为这一领域带来了革命性的变化:
- 高效性:AI 能够快速处理大量文本,生成标签和摘要在短时间内完成,大大提高了内容发布的效率。
- 准确性:通过机器学习算法,AI 能够准确识别文章的主题和关键信息,生成相关度高的标签和摘要。
- 个性化:AI 可以根据不同的内容和风格需求,定制化的生成标签和摘要,满足多样化的内容创作需求。
AI 生成标签和摘要的实现过程
目前正在使用 TianliGPT, 它是一个专业的文字摘要生成工具,你可以将需要提取摘要的文本内容发送给TianliGPT,稍等一会他就可以给你发送一个基于这段文本内容的摘要。
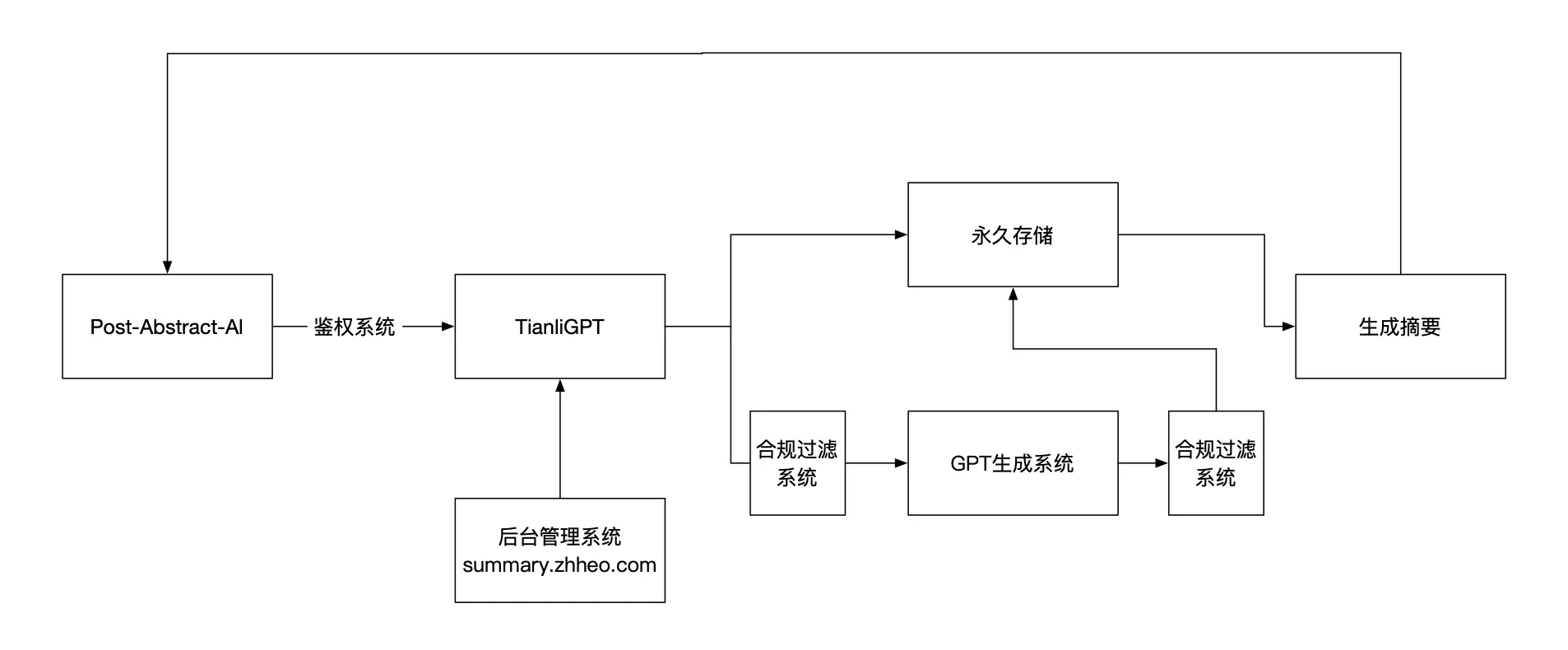
- 实时生成的摘要
- 自动生成,无需人工干预
- 一次生成,再次生成无需消耗key
- 包含文字审核过滤,适用于中国大陆
- 支持中国大陆访问
到 爱发电中购买,原价10元5万字符(Heo限量限时折扣9元)。请求过的内容再次请求不会消耗key,可以无限期使用。
作者同时提供多种博客的插件, 接入方式也非常简单.
但是今天 TianliGPT 不是我们的重点, 重点是利用本地自建的 LLM 服务来生成摘要和标签.
实现方式也非常简单, 我所使用的 安知鱼主题 中集成了 TianliGPT, 只需要配置 key 和 Referer 即可, 其中还有一个可选项:
post_head_ai_description:
enable: true
gptName: xxx
mode: local # 默认模式 可选值: tianli/local
switchBtn: true # 可以配置是否显示切换按钮 以切换tianli/local
...在页面上可以选择使用 local 还是 tianli 来生成摘要:

如果切换到本地, 则会显示自定义的 GPT 名称与自定义摘要内容:

在文章的 Front-matter配置 ai: true 使用 tianli gpt 需将 mode 改为 tianli 然后在需要 ai 摘要的文章的 Front-matter 配置 ai: true
如果使用 local,需要按照以下方式配置
---
title: AnZhiYu主题快速开始
ai:
- 本教程介绍了如何在博客中安装基于Hexo主题的安知鱼主题,并提供了安装、应用主题、修改配置文件、本地启动等详细步骤及技术支持方式。教程的内容针对最新的主题版本进行更新,如果你是旧版本教程会有出入。
- 本文真不错
---意思是只要在 Front-matter 中配置 ai 标签即可在博客中显示摘要, 那么我们的目标就很明确了:
- 使用 LLM 生成文章摘要;
- 填写到文章的
ai标签中; - 将
mode设置为local, 默认使用本地的摘要; - 借助 TianliGPT 在页面显示自定义摘要;
更多支持TianliGPT的项目
Post-Summary-AI - 轻笑开发的博客摘要生成工具
hexo-ai-excerpt - 在本地部署时添加AI摘要
搭建 LLM 服务
这个我相信老铁们都很熟悉了. 为了偷了懒我直接在 Mac mini M2 上运行了一个 Ollama 服务, 使用 glm4 模型来为文章生成摘要. 我相信在 macOS 上部署 Ollama 应该是一种最简单快速部署 LLM 的方式了, 相关教程也非常多, 这里就不再赘述了.
需要说明的是为了让其他主机能够使用 LLM 服务, 需要特殊配置一下:
# 允许跨域
launchctl setenv OLLAMA_ORIGINS "*"
# 修改 bind
launchctl setenv OLLAMA_HOST "0.0.0.0"自动化
脚本
先来一个简单的脚本, 通过调用 Ollama 的 API 来获取文章摘要:
import requests
import json
import re
def generate_summary(content, model="default"):
"""
调用 Ollama API 生成博客摘要。
:param content: 博客内容 (字符串)
:param model: 使用的 Ollama 模型 (默认是 'default')
:return: 生成的摘要 (JSON 字符串)
"""
# 构造 prompt
prompt = f"""
你是一个专业的内容总结生成助手。你的任务是为给定的博客内容进行总结, 字数在 100 字内。
请分析'CONTENT START HERE'和'CONTENT END HERE'之间的文本,以下是规则:
1. 仅返回一个完整的总结,不要添加额外的信息。
2. 如果内容中包含 HTML 标签,请忽略这些标签,仅提取文本内容进行分析。
以下是需要处理的博客内容:
CONTENT START HERE
{content}
CONTENT END HERE
你必须以JSON格式响应,键为'summary',值是字符串格式的总结内容。
"""
# print(blog_content)
# 设置 Ollama API 的 URL
url = f"http://localhost:11434/api/generate"
data = {
"model": model,
"prompt": prompt,
"format": "json",
"stream": False
}
# 发送 POST 请求到 Ollama API
try:
response = requests.post(url, json=data, stream=False)
response.raise_for_status() # 检查请求是否成功
data = response.json()
# 提取生成的摘要
if "response" in data:
return data["response"]
else:
print("没有从响应中获取到摘要内容!")
return None
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
return None
if __name__ == "__main__":
# 输入博客内容
# blog_content = """
# 标题:Ollama 模型的使用方法
# 内容:Ollama 是一个强大的语言模型框架,可以用于生成内容、总结文档等。它支持多种模型类型,
# 并且可以通过简单的 API 调用来实现复杂的文本生成任务。
# 在这篇博客中,我们将介绍如何使用 Ollama,以及如何通过 Python 调用其 API 来生成内容。
# """
with open("md 文档路径", "r", encoding="utf-8") as file:
blog_content = file.read()
# 删除多余空行,但保留段落间的分隔
blog_content = re.sub(r'\n\s*\n', '\n', blog_content)
# 删除每行行首和行尾的多余空白符
blog_content = "\n".join(line.strip() for line in blog_content.splitlines())
# 生成摘要
summary = generate_summary(blog_content, model="glm4")
# 输出摘要
if summary:
print(summary)保存为 generate_summary.py , 然后运行: python generate_summary.py, 输出结果:
{
"summary": "文章讲述了从书房设备升级到万兆网络的过程和经验。主要涉及到硬件升级、网络环境搭建、问题解决以及性能优化等方面。通过一周时间的努力,实现了上传和下载速度接近或达到理论值的效果。文中还提到了将书房主要设备升级为支持更大带宽的可能方案,并链接了多个与HomeLab相关主题的文章,如硬件、服务、数据管理等。"
}简直是一气呵成.
我的目标是将博客部署到云平台之前, 自动为博客生成摘要和 tags, 所以我们需要一个脚本去修改 Front-matter 中 ai 和 tags 这 2 个标签的内容, 我们先来看自动化脚本:
import os
import sys
import requests
import re
from io import StringIO
from ruamel.yaml import YAML
import json
import re
from datetime import datetime
"""
生成标签和总结并替换原文本的内容
"""
def log(message):
"""
打印日志信息,包含时间戳。
"""
print(f"[{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}] {message}")
# 自定义 YAML Dump 函数,保持缩进和格式
def dump_yaml(data):
yaml = YAML()
yaml = YAML()
yaml.preserve_quotes = True
yaml.indent(mapping=2, sequence=4, offset=2)
# 使用 StringIO 来捕获输出
stream = StringIO()
yaml.dump(data, stream)
# 获取字符串值并返回
return stream.getvalue()
def get_all_md_files(directory, exclude_dir=None):
"""
遍历指定目录,获取所有 Markdown 文件(排除指定目录)。
"""
md_files = []
for root, dirs, files in os.walk(directory):
# 排除指定的目录s
if exclude_dir and os.path.abspath(exclude_dir) in os.path.abspath(root):
continue
for file in files:
if file.endswith('.md'):
md_files.append(os.path.join(root, file))
return md_files
def find_md_file(base_dir, filename, exclude_dir=None):
"""
在指定目录中查找特定的 Markdown 文件(排除指定目录)。
"""
for root, dirs, files in os.walk(base_dir):
# 排除指定的目录
if exclude_dir and os.path.abspath(exclude_dir) in os.path.abspath(root):
continue
for file in files:
if file == filename:
return os.path.join(root, file)
return None
def replace_ai_tags_in_md(md_file, base_dir, publish_dir):
"""
替换 Markdown 文件中的 `ai` 标签,并保存到发布目录。
"""
log(f"开始处理文件: {md_file}")
with open(md_file, 'r', encoding='utf-8') as file:
content = file.read()
# 提取 Front-matter 部分
front_matter_pattern = r"---\n(.*?)\n---\n"
match = re.match(front_matter_pattern, content, re.DOTALL)
if not match:
log(f"文件 {md_file} 不包含有效的 Front-matter,跳过处理。")
return
front_matter = match.group(1)
body = content[match.end():] # Markdown 正文内容
# 使用 YAML 解析 Front-matter
data = YAML().load(front_matter)
# 检查 ai 标签
md_ai_tag = data.get('ai')
description_tag = data.get('description')
# 判断是否需要生成摘要
need_generate_summary = not isinstance(md_ai_tag, list) or not description_tag
need_update =False
if need_generate_summary:
# 替换 `ai` 标签内容
ai_data = generate_summary_and_tags(body) # 调用摘要生成函数
summary = ai_data.get("summary", "").strip()
if summary:
if not isinstance(md_ai_tag, list):
data['ai'] = [summary] # 设置或替换 ai 标签
log(f"文件 {md_file} 生成 ai 摘要")
if not description_tag:
data['description'] = summary # 设置或替换 description 标签
log(f"文件 {md_file} 生成 description 标签")
need_update = True
else:
log(f"未获取摘要,跳过文件")
md_tags = data.get('tags')
if not isinstance(md_tags, list):
# 替换 `tags` 标签内容
ai_data = generate_summary_and_tags(body) # 调用摘要生成函数
tags = ai_data.get("tags", "")
if tags:
data['tags'] = tags
log(f"文件 {md_file} 生成 tags")
need_update = True
else:
log(f"未获取 tags,跳过文件")
if need_update:
# 将更新后的 Front-matter 转换回 YAML 格式
updated_front_matter = dump_yaml(data)
updated_content = f"---\n{updated_front_matter}---\n{body}"
# 保存更新后的内容到原文件
with open(md_file, 'w', encoding='utf-8') as file:
file.write(updated_content)
log(f"已更新文件: {md_file}")
else:
log(f"不需要更新文件")
def generate_summary_and_tags(content):
# 删除多余空行,但保留段落间的分隔
content = re.sub(r'\n\s*\n', '\n', content)
# 删除每行行首和行尾的多余空白符
content = "\n".join(line.strip() for line in content.splitlines())
# 生成摘要
summary = generate_summary_from_ai(content, model="qwen2")
# 解析 JSON 格式字符串,提取 summary 的值
try:
return json.loads(summary)
except json.JSONDecodeError as e:
log(f"解析 JSON 数据失败: {e}")
return ''
def generate_summary_from_ai(content, model="default"):
"""
调用 Ollama API 生成博客摘要。
:param content: 博客内容 (字符串)
:param model: 使用的 Ollama 模型 (默认是 'default')
:return: 生成的摘要 (字符串)
"""
# 构造 prompt
prompt = f"""
你是一个专业的内容总结生成助手。你的任务是为给定的博客内容进行总结以及帮助进行自动生成标签。
请分析'CONTENT START HERE'和'CONTENT END HERE'之间的文本,以下是总结规则:
1. 生成的总结内容,长度在 100 到 300 字符之间。
2. 仅返回一个完整的总结,不要添加额外的信息。
3. 如果内容中包含 HTML 标签,请忽略这些标签,仅提取文本内容进行分析。
下面是标签生成规则:
- 目标是多种多样的标签,包括广泛类别、特定关键词和潜在的子类别。
- 标签语言必须为中文。
- 标签最好是文案中的词, 比如 HomeLab, Java 等, 这些应该按照原文中出现的词来生成。
- 如果是著名网站,你也可以为该网站添加一个标签。如果标签不够通用,不要包含它。
- 内容可能包括cookie同意和隐私政策的文本,在标签时请忽略这些。
- 目标是3-5个标签。
- 如果没有好的标签,请留空数组。
以下是需要处理的博客内容:
CONTENT START HERE
{content}
CONTENT END HERE
你必须以JSON格式响应,键为'summary',值是字符串格式的总结内容, 键为'tags',值是字符串标签的数组。
"""
# print(blog_content)
# 设置 Ollama API 的 URL
url = f"http://localhost:11434/api/generate"
data = {
"model": model,
"prompt": prompt,
"format": "json",
"stream": False
}
# 发送 POST 请求到 Ollama API
try:
response = requests.post(url, json=data, stream=False)
response.raise_for_status() # 检查请求是否成功
data = response.json()
# 提取生成的摘要
if "response" in data:
return data["response"]
else:
print("没有从响应中获取到摘要内容!")
return None
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
return None
def main():
args = sys.argv[1:]
script_dir = os.path.dirname(os.path.abspath(__file__))
base_dir = os.path.join(script_dir, '..', 'source/_posts')
publish_dir = os.path.join(base_dir, 'publish')
# 初始化要处理的 Markdown 文件列表
md_files_to_process = []
"""
1. 不传任何参数, 则处理 source/_posts 下所有的文档(不包括 publish 目录);
2. 传入年份参数,则处理指定年份的 Markdown 文件(不包括 publish 目录);
3. 传入 Markdown 文件名,则处理指定的 Markdown (文件不包括 publish 目录);
"""
if not args:
# 处理所有 Markdown 文件
md_files_to_process = get_all_md_files(base_dir, exclude_dir=publish_dir)
elif len(args) == 1 and args[0].isdigit():
# 处理指定年份的 Markdown 文件
year_dir = os.path.join(base_dir, args[0])
if os.path.isdir(year_dir):
md_files_to_process = get_all_md_files(year_dir, exclude_dir=publish_dir)
else:
log(f"年份目录 {args[0]} 不存在。")
return
elif len(args) == 1 and args[0].endswith('.md'):
# 处理指定的 Markdown 文件
md_filename = args[0]
md_file = find_md_file(base_dir, md_filename, exclude_dir=publish_dir)
if md_file:
md_files_to_process.append(md_file)
else:
log(f"未找到 Markdown 文件 {md_filename}。")
return
else:
log("参数数量错误。")
return
# 循环处理所有确定的 Markdown 文件
for md_file in md_files_to_process:
replace_ai_tags_in_md(md_file, base_dir, publish_dir)
if __name__ == "__main__":
main()逻辑也非常简单了:
- 自动获取 md 文件内容, 简单的处理一下后给 LLM 生成摘要和标签;
- 自动替换
Front-matter中的ai和tags标签;
这里需要先说一下我的 Hexo 博客的目录结构:
.
├── script
│ ├── 其他各种脚本
│ └── generate_summary_and_tags_and_replace.py # 就是上面的脚本
├── source
│ ├── _posts
│ │ ├── 2012
│ │ ├── 2013
│ │ ├── 2014
│ │ ├── 2015
│ │ ├── 2016
│ │ ├── 2017
│ │ ├── 2018
│ │ ├── 2019
│ │ ├── 2020
│ │ ├── 2021
│ │ ├── 2022
│ │ ├── 2023
│ │ ├── 2024
│ │ └── publish
│ └── 其他目录
├── makefile
└── themes
- 我的所有脚本都是在
script目录下; _posts下按照年份划分不同的目录;makefile用于部署工作流配置;
hexo-deploy-workflow
这个不是 Hexo 的插件, 是我通过 markfile 实现的一个部署工作流程:
# 定义伪目标,避免与文件名冲突
.PHONY: clean_images convert_and_rename upload_images generate_summary_tags push deploy-m920x deploy-github clean
########## 需要终端在 hexo 顶层目录才能正常执行
# 默认目标
all: clean_images convert_and_rename upload_images generate_summary_tags push deploy-m920x deploy-github clean
# 删除未被引用的图片, 不传任何参数则全部处理, 传 2023 则只处理 2023 目录下的文件, 传 md 文件名, 则只处理这一个文件
clean_images:
@echo "==================Step 1: Cleaning images=================="
python script/clean_images.py
# 将图片转换为 webp 且重命名(年月日时分秒_8位随机字符串.webp)
convert_and_rename:
@echo "==================Step 2: Cleaning images=================="
python script/convert_and_rename.py
# 上传图片
upload_images:
@echo "==================Step 3: Cleaning images=================="
python script/upload_images.py
generate_summary_tags:
@echo "==================Step 3: Cleaning images=================="
python script/generate_summary_and_tags_and_replace.py
# 执行 git-push.sh
push: generate_summary_tags
@echo "==================Step 4: Pushing changes to Git=================="
script/git-push.sh "删除重复的文章"
# 执行 deploy.sh
deploy-m920x: push
@echo "==================Step 5: Deploying application=================="
script/deploy.sh
deploy-github: push
@echo "==================Step 6: Deploying Github=================="
hexo deploy
clean:
@echo "==================Step 7: Cleaning up=================="
hexo clean && rm -rf .deploy_git其中涉及到摘要生成并发布的步骤为:
generate_summary_tags:
@echo "==================Step 3: Cleaning images=================="
python script/generate_summary_and_tags_and_replace.py
# 执行 git-push.sh
push: generate_summary_tags
@echo "==================Step 4: Pushing changes to Git=================="
script/git-push.sh "删除重复的文章"意思是只要我执行 make push, 即会在执行 push 之前先执行 generate_summary_tags, 通过 makefile 的编排实现了一个简单的工作流.
效果
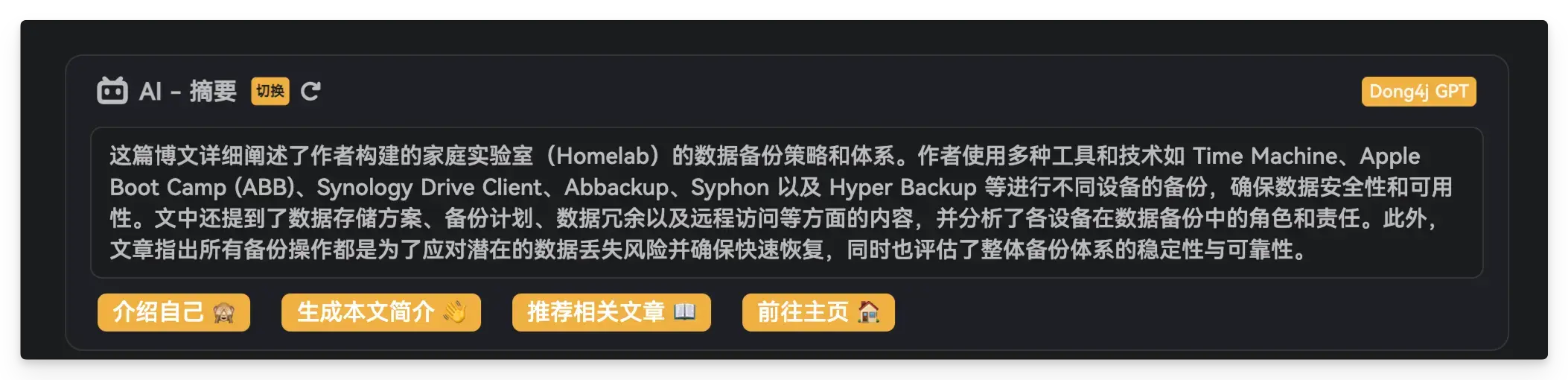
脚本处理后的 md 文件:
---
title: HomeLab数据备份:打造坚实的数据安全防线
ai:
- 这篇博文详细阐述了作者构建的家庭实验室(Homelab)的数据备份策略和体系。作者使用多种工具和技术如Time Machine、Apple Boot Camp
(ABB)、Synology Drive Client、Abbackup、Syphon以及Hyper Backup等进行不同设备的备份,确保数据安全性和可用性。文中还提到了数据存储方案、备份计划、数据冗余以及远程访问等方面的内容,并分析了各设备在数据备份中的角色和责任。此外,文章指出所有备份操作都是为了应对潜在的数据丢失风险并确保快速恢复,同时也评估了整体备份体系的稳定性与可靠性。
swiper_index: 7
top_group_index: 7
tags:
- Homelab
- Data Backup
- MacOS
- Linux
- Synology
- Time Machine
- ABB
- Docker
- WebDAV
- Aliyun Pan
categories:
- HomeLab
cover: /images/cover/20241229154732_oUxZug2L.webp
date: 2020-04-25 00:00:00
main_color:
description: 这篇博文详细阐述了作者构建的家庭实验室(Homelab)的数据备份策略和体系。作者使用多种工具和技术如Time Machine、Apple
Boot Camp (ABB)、Synology Drive Client、Abbackup、Syphon以及Hyper Backup等进行不同设备的备份,确保数据安全性和可用性。文中还提到了数据存储方案、备份计划、数据冗余以及远程访问等方面的内容,并分析了各设备在数据备份中的角色和责任。此外,文章指出所有备份操作都是为了应对潜在的数据丢失风险并确保快速恢复,同时也评估了整体备份体系的稳定性与可靠性。
---
总结
不是说 TianliGPT 这类在线服务不好用或者太贵用不起, 只是觉得本地这么折腾下来更有意思.
未来我相信随着个人设备的性能足够强劲或者技术发展到 AI 模型也能够在廉价设备上运行时, 在人们更加关注隐私与安全性的时候, 本地模型才是最终的归属.